ABBYY FineReader Engine
 >
> - SDK >
- ABBYY FineReader Engine
-
ABBYY FineReader Engine 이란?소프트웨어 개발키트 ABBYY FineReader Engine을 사용하면 소프트웨어 개발자가 종이문서, 이미지 또는 디스플레이의 텍스트를 추출하는 응용 프로그램을 쉽게 만들 수있습니다. FineReader Engine은 응용 프로그램에 강력한 텍스트인식 기능, PDF 변환 기능, 데이터 캡처 기능을 제공합니다. 하드카피를 검색 가능한 PDF, Word, Excel 문서로 변환하고사진, 스크린샷 이미지에서 즉시 데이터를 사용할 수 있게 해줍니다.
강력하고 뛰어난 성능의 인공지능 기반 OCR 엔진으로 200개 이상 언어의 인쇄체 텍스트, 필기체(영문,숫자), 광학 기호, 바코드 인식을 제공합니다.
필기체(영문,숫자), 광학 기호, 바코드 인식을 제공합니다.
PDF 처리를 위한 다양한 API를 통해 다양한 PDF 형식의 문서 처리를 지원합니다. 스캐닝한 이미지(TIFF, JPEG, Image only PDF) 등 이미지 형태의 파일을 검색 가능한 PDF또는 PDF/A 형식의 파일로 쉽게 변경할 수 있습니다.
스캐닝한 이미지(TIFF, JPEG, Image only PDF) 등 이미지 형태의 파일을 검색 가능한 PDF또는 PDF/A 형식의 파일로 쉽게 변경할 수 있습니다.
인공지능(AI) 머신러닝(ML) 등 최신 기술을 통해 다국어 문서에 대한 뛰어난 인식 정확도를 제공하며 원본 문서를 그대로 반영하면서 검색 및 편집이 가능한 문서로 변환할 수 있습니다.
원본 문서를 그대로 반영하면서 검색 및 편집이 가능한 문서로 변환할 수 있습니다.
문서 처리시 멀티코어 CPU를 이용한 병렬 처리가 가능합니다. 클라우드 및 가상환경을 지원하며 빠르고, 유연하고, 확장성이 높은 처리 환경을 제공합니다.
클라우드 및 가상환경을 지원하며 빠르고, 유연하고, 확장성이 높은 처리 환경을 제공합니다.
높은 정확도의 OCR 시스템을 제공하여 수기 검증에 필요한 노력을 최소화 할 수 있습니다. 선도적인 소프트웨어 및 하드웨어 글로벌 기업 제품에 ABBYY의 프리미엄 OCR 기술이 적용되어있습니다.
선도적인 소프트웨어 및 하드웨어 글로벌 기업 제품에 ABBYY의 프리미엄 OCR 기술이 적용되어있습니다.
Windows, Linux 또는 Mac용 데스크톱 또는 서버 응용 프로그램을 만들어 클라우드 또는 가상 컴퓨터에 적용할 수 있습니다. 다양한 OCR 기능은 DMS, ERP, RPA, 보험, 은행 업무, 건강관리,법률 및 기계 비전과 같은 다양한 분야의 응용 프로그램에 이용 가능 합니다.
컴퓨터에 적용할 수 있습니다. 다양한 OCR 기능은 DMS, ERP, RPA, 보험, 은행 업무, 건강관리,법률 및 기계 비전과 같은 다양한 분야의 응용 프로그램에 이용 가능 합니다.
-
ABBYY FineReader Engine 주요기능-1
인식 기능l CPU의 멀티 코어 활용자동으로 멀티 코어 사용 여부를 감지. 쉽게 설정 변경 및 실행 프로세스 수 조정가능l 208개의 OCR (인쇄체) 언어 지원아시아 : 한국어, 중국어 (간/번), 일본어, 베트남어, 태국어, 히브리어 등유럽어 : 라틴, 키릴, 그리스, 아르메니아 알파펫 기반 언어 등아랍어 OCR 세계 최고 수준 ** 전체 언어 목록 보기 (영문)문서 내에 다중 언어 자동 식별l 26개의 BCR (명함인식) 언어 지원한국어, 중국어 (간/번), 일본어 비롯 유럽어 등 명함 인식l 126개의 ICR (필기체) 언어 지원라틴, 키릴, 그리스 문자에 기반한 38여개 주요 언어 (사전 지원)22개 국가/ 지역의 다양한 필체 지원l 광학 바코드 (OBR) 인식1차원 바코드 16종 인식, QR코드, PDF 471, Aztec, DataMatrix 등 2차원 바코드 인식빠른 바코드 추출 기능 문서의 모든 각도에서 바코드를 자동으로 감지 및 인식l OMR (Optical Mark Recognition) 인식률 99.995%
 l 전체 텍스트 인식 및 필드 인식전체 텍스트 인식 – 문서 변환 목적 문서 파일(DOC,PDF등)로 내보내기.필드 인식 – 데이터 수집 목적 XML, 데이터베이스로 내보내기
l 전체 텍스트 인식 및 필드 인식전체 텍스트 인식 – 문서 변환 목적 문서 파일(DOC,PDF등)로 내보내기.필드 인식 – 데이터 수집 목적 XML, 데이터베이스로 내보내기
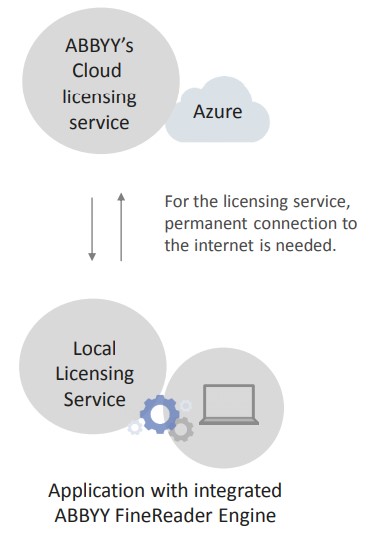
l Cloud & VM 지원Amazon EC2, Azure Cloud Services, VMWare, Oracle Vitual Box 등의클라우드 및 가상환경 지원
다양한 입력 포맷 / 출력 포맷l 입력 이미지 파일 포맷BMP, PCX, DCX, GIF, PNG, DjVu, PDF, JPEG, JPEG2000, JBIG2, TIFF 등l 메모리 이미지 포맷Raw, Bitmap (HBITMAP), DIBl 스캔 – TWAIN 인터페이스/ 파인리더 문서 스캔 인터페이스 지원l 저장 문서 포맷MS Office formats, including Office 2007 (DOC,DOCX,XLS,XLSX,PPT/PPTX,ODT)RTF,HTML,CSV,DBF,TXTEPUB,FB2 (E-BOOK 변환)XML (인식 결과를 포함한 전체 포맷 복원에 필요한 정보를 XML로 저장)-XPS 내보내기 추가 (윈도우)-HTML5, ALTO3.1 내보내기 추가-PDF 2.0, PDF/UA, PDF/A-2b, PDF/A-3b 내보내기 추가
 이미지 전처리l 인식 품질 향상을 위한 이미지 전처리이미지 기울기 자동 조정, 잡영 (노이즈) 제거배경 문양 제거 및 적응형 이진화양면 스캔된 이미지 분할 후 개별 기울기 보정이미지 방향 자동 식별 (90, 180, 270도)컬러 문자 영상 및 배경 이미지 처리, 컬러 필터링개별 필드 이미지에 대한 잡영 제거 , 테두리 제거
이미지 전처리l 인식 품질 향상을 위한 이미지 전처리이미지 기울기 자동 조정, 잡영 (노이즈) 제거배경 문양 제거 및 적응형 이진화양면 스캔된 이미지 분할 후 개별 기울기 보정이미지 방향 자동 식별 (90, 180, 270도)컬러 문자 영상 및 배경 이미지 처리, 컬러 필터링개별 필드 이미지에 대한 잡영 제거 , 테두리 제거
l Camera OCR™
디지털 카메라로 촬영한 이미지에 대한 보정
* 3D 원근 왜곡 수정
* 흐려진 이미지 보정

* ISO 노이즈 보정

-
ABBYY FineReader Engine 주요기능-2
문서 구조 APIl 정확한 문서 구조 및 레이아웃 유지 기능ADRT 적응형 문서인식 기술 탑재 문서 전체의 논리적 구조 분석 및 이해문서 차원의 형식 복원 (문단 머리말 꼬리말 각주 하이퍼링크 페이지 번호 등 복원)
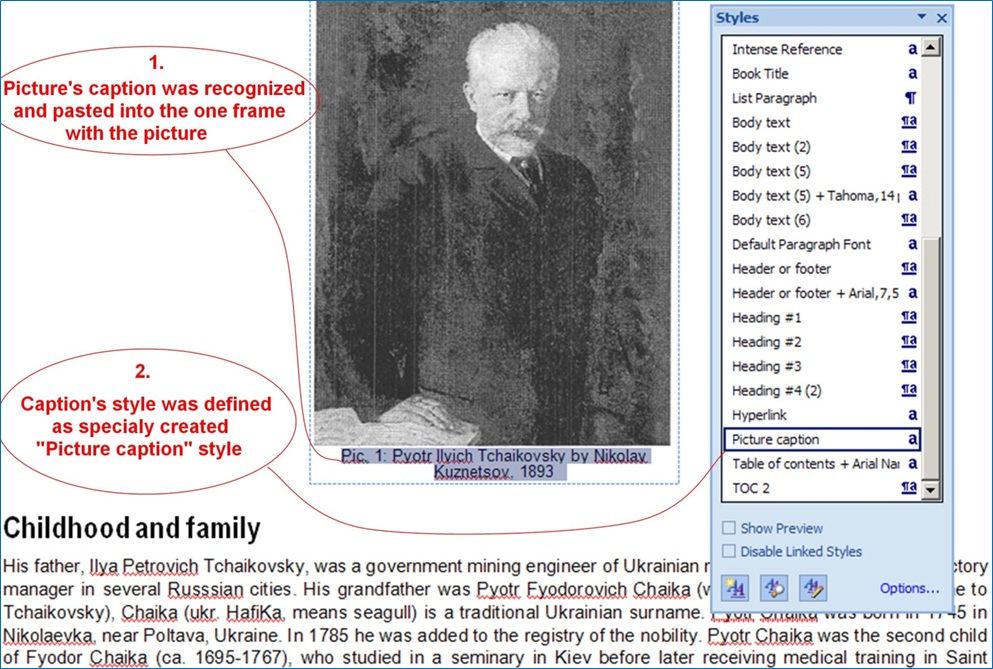
l 필드 / 영역 분석
문서 인덱싱을 위한 사용자 지정 필드/영역에 대한 분석 및 추출
비주얼 컴포넌트l 비주얼 컴포넌트 표시 및 제어 API 제공l 스캔 인터페이스 – TWAIN 호환 스캐너에 대한 제어l 문서 뷰어문서 이미지의 썸네일 보기, 테이블 형식으로 상세보기 인식 진행 상태 표시l 이미지 뷰어전체 이미지 표시, 인식블록의 생성을 위한 툴 제공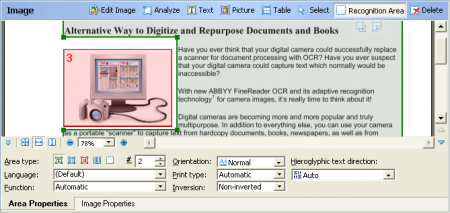
l 텍스트 에디터인식 결과 표시 및 불확실한 문자에 대한 하이라이트기본적인 텍스트 서식 툴 제공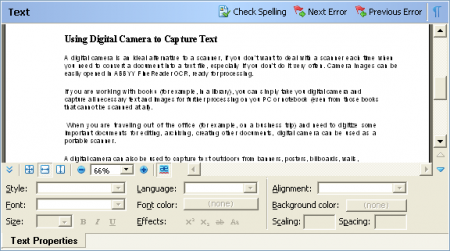
l 텍스트 검증기텍스트 주요 부분의 ‘줌’ 보기, 불확실한 문자로 인식된 결과에 대한 검증 툴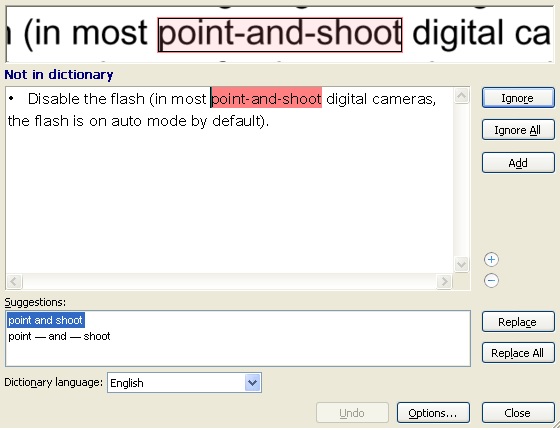
l Windows, Linux and OS X 동시지원l 64-bit native supportX64 어플리케이션에 C++ DLL을 바로 링크 가능 (COM proxy 불필요).NET / Java 상호 연동 가능
l 다양한 방식의 분류기반 적용
l 이미지 기반 분석-CNN(Convolutional neural network)를 사용하여 외관으로 이미지를 구별하는 분류 방식 (FAST)l 텍스트 기반 분석-전체 페이지에 OCR 처리를 하여 내용으로 구별하는 분류 방식 (SLOW)두 방식을 같이 사용할 수도 있고 따로도 사용 가능또한 속도 모드와 정확성모드 중 하나를 선택하여 트레이닝 후 통계를 볼 수 있음l 테이블 재구성 성능 향상-docx로 내보낼 때 테이블 테두리 재구성-txt로 내보낼 때 레이아웃 보존 기능 향상-xlsx에 내보낼 때 셀 테두리 색을 감지하고 내보냄l 명함 인식 API명함 인식 기능의 API Full set 제공한/중/일/영 포함한 27개국 언어 인식vCard, CSV, XML 포맷으로 저장여러 장의 명함 자동 분할 기능명함 필드 정보 추출- 이름, 회사명, 직책, 주소/직장주소, 전화/휴대폰/팩스, 이메일, 웹사이트l 한국어 OCR 성능 개선
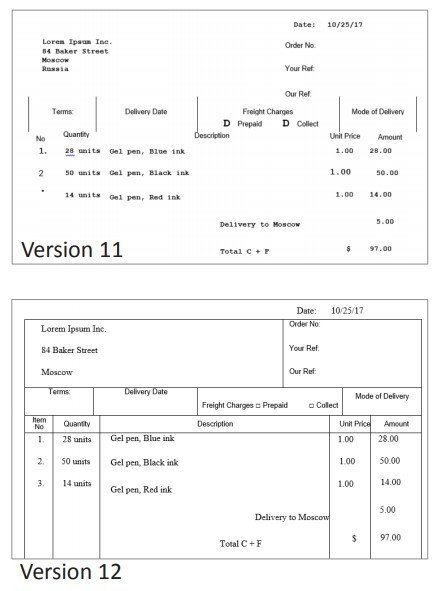
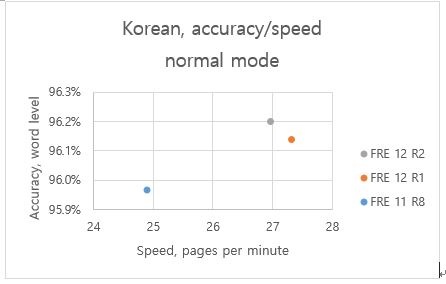
주요 기술 변경으로 인한 OCR 성능 개선- 한국어 normal mode의 경우 전 버전 대비 속도 12% 상승 및 정확성 0.2% 향상
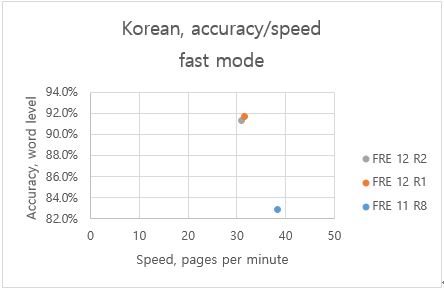
-한국어 Fast mode의 경우 전 버전 대비 정확성 10.1%향상
-
ABBYY FineReader Engine 새 기능
l Cloud & VM 지원클라우드 보호 메커니즘을 사용하는 새로운 유형의 라이선스 사용 가능특정 호스트에 바인딩 되지 않으며 인터넷을 통해 라이선스를 확인함.Amazon EC2, Azure Cloud Services, VMWare, Oracle Virtual Box등의 다양한 환경을지원하며 지원되는 플랫폼의 Docker Container 에서도 실행가능
l 분류 기능 향상
l 이미지 기반 분석-CNN(Convolutional neural network)를 사용하여 외관으로 이미지를 구별하는 분류 방식 (FAST)
l 텍스트 기반 분석-전체 페이지에 OCR 처리를 하여 내용으로 구별하는 분류 방식 (SLOW)두 방식을 같이 사용할 수도 있고 따로도 사용 가능또한 속도 모드와 정확성모드 중 하나를 선택하여 트레이닝 후 통계를 볼 수 있음
l 테이블 재구성 성능 향상-docx로 내보낼 때 테이블 테두리 재구성-txt로 내보낼 때 레이아웃 보존 기능 향상-xlsx에 내보낼 때 셀 테두리 색을 감지하고 내보냄
l 내보내기 성능 개선PDF 내보내기시 256bit AES 암호화 추가 지원 (패스워드로 유니코드 사용가능)XML 내보내기 기능 향상- 저장 지연 없음, 리스트 요소 직접 내보내기 가능, 탭이나 공백에 대한 정보 내보내기 가능추가된 내보내기 형식-XPS 내보내기 추가 (윈도우)-HTML5, ALTO3.1 내보내기 추가-PDF 2.0, PDF/UA, PDF/A-2b, PDF/A-3b 내보내기 추가
l 신규 OCR 언어 추가버마어, 페르시아어(이란어) 추가
l OCR 성능 개선주요 기술 변경으로 인한 OCR 성능 개선
- 한국어 normal mode의 경우 전 버전 대비 속도 12% 상승 및 정확성 0.2% 상승
-한국어 Fast mode의 경우 전 버전 대비 정확성 10.1%상승
 l 스캔 기능의 자동처리 단계 옵션 추가빈 페이지 감지페이지 잘라내기Skew 보정색채 검출
l 스캔 기능의 자동처리 단계 옵션 추가빈 페이지 감지페이지 잘라내기Skew 보정색채 검출 -
ABBYY FineReader Engine 라이선스
l 시험판 라이선스무상 (시험판 사용계약서(TSLA) 체결 필요)21일 / 5,000 페이지 처리 가능
l 개발자 라이선스FineReader 엔진을 사용하여 응용프로그램을 개발 / 테스트 할 수 있는 라이선스유상 (구매 전 SDK 사용 계약서 체결)기능에 제한 없으며, 월 10,000 페이지 처리 가능
l 런타임 라이선스응용프로그램에서 FineReader 엔진 기능을 실행하기 위해 필요한 라이선스라이선스 가격은 선택 사항 적용에 변동FineReader 엔진 기능: 검색가능한 PDF 저장, UI 컴포넌트, 1D&2D 바코드, OCR & OMROCR 처리량: PPY (연간 최대 OCR 처리 페이지), 가용 CPU 코어 수, 또는 번들 수량 (카피/유니트)네트워크 지원OCR 언어: 아시아 언어, Latin 계열 유럽어, Cyril 계열 유럽어, 아랍어
l 유지보수SMUA (Software Maintenance & Upgrade Assurance):소프트웨어를 최신 상태로 유지하기 위한 보장. 버전 업그레이드 포함 (유상/연간)기술 지원 및 컨설팅 (별도 협의)
-
ABBYY OCR SDK World's Best OCR SDK 'ABBYY OCR Engine'
ABBYY FineReader Engine
- 튜토리얼 1 이니셜라이즈 및 문서 처리
FineReader Engine 초기 설정 방법과 FineReader Engine 이 다른 파라미터의 문서를 인식하는 방법,
처리방법, 결과를 내보내는 방법을 확인할 수 있습니다.
ABBYY FineReader Engine
- 튜토리얼 2 고유 GUI 만들기 위한 구성 요소 사용 및 테스트 인식 파라미터
이 비디오에서는 SDK의 코드 샘플 라이브러리에 제공된 UI 구성 요소를 사용하여 응용 프로그램의 GUI를
작성하는 방법을 볼 수 있습니다.
시각적 구성 요소 데모 응용 프로그램을 사용하여 인식 작업에 적합한 프로세싱 프로파일을 쉽게 찾는
방법을 확인하실 수 있습니다.
-
ABBYY FineReader Engine 주요 구축 사례
-
ABBYY FineReader Engine 기술 사양
Windows
l 시스템 요구 사항PC with x86-compatiable processor (1 GHz or higher)
l 운영체제Windows Server 2016Windows 10Windows 8.1Windows Server 2012Windows 8Windows Server 2008 R2 SP1Windows 7 SP1l 클라우드 컴퓨팅 플랫폼Microsoft AzureAzure App ServicesAzure Cloud ServicesAzure Service FabricAzure Virtual MachinesAmazon EC2
l 가상환경Microsoft Hyper-V Server 2008Microsoft Hyper-V Server 2008 R2 SP1Microsoft Hyper-V Server 2012Microsoft Hyper-V Server 2012 R2Microsoft Hyper-V Server 2016Oracle VM VirtualBox 5.2Parallels Desktop for Mac 13.0.1VMware ESXi 6.5VMware Workstation Pro 14.0.0(지원되는 플랫폼의 Docker Container 에서도 실행 가능)l 메모리문서 1페이지 처리시 : 최소 400 MB RAM, 권장 1 GB RAM멀티 페이지 처리시 최소 : 1 GB RAM, 권장 1.5 GB RAM병렬 처리시 : 450+(number of cores) x 350 MB RAM해당 언어의 병렬 처리시 (Arabic, Chinese, Japanese, or Korean languages): 750+ (number of cores) x 850 MB RAMl 하드 디스크 공간라이브러리 설치의 경우 1400MB응용 프로그램 실행 시 100BMB, 다중 페이지 문서의 경우 페이지 당 추가로 15MB 필요
Linux
l 시스템 요구 사항PC with x86-compatible processor (1 GHz or higher, SSE 와 SSE2 instruction sets 지원 필요)
l 운영체제Fedora 31, 30, 29Red Hat Enterprise Linux 8.1, 7.7, 6.10SUSE Linux Enterprise Server 15 SP1, 12 SP4, 11 SP4Debian GNU/Linux 10.2, 9.11, 8.11Ubuntu 19.10, 19.04, 18.04.3 LTS, 16.04.6 LTS, 14.04.6 LTSCentOS 8.0, 7.7, 6.10ALT Linux 9.0, 8.2 (software and online protection only)Amazon Linux AMI 2018.03l 클라우드 컴퓨팅 플랫폼Microsoft Azure Virtual MachinesAmazon EC2l 가상환경Microsoft Hyper-V Server 2012 R2Microsoft Hyper-V Server 2016Oracle VM VirtualBox 5.2VMware ESXi 6.5VMware Workstation Player 12.5VMware Workstation Pro 14.0.0Linux KVM(지원되는 플랫폼의 Docker Container 에서도 실행 가능)l 메모리문서 1페이지 처리시 : 최소 400 MB RAM, 권장 1 GB RAM멀티 페이지 처리시 최소 : 1 GB RAM, 권장 1.5 GB RAM병렬 처리시 : 450+(number of cores) x 350 MB RAM해당 언어의 병렬 처리시 (Arabic, Chinese, Japanese, or Korean languages): 750 + (number of cores) x 850 MB RAM요구 Tmpfs 크기 : 4GB + 1GB * (CPU CORE 개수)요구 Swap 크기 : 4GB + 1GB * (CPU CORE 개수)l 하드 디스크 공간라이브러리 설치의 경우 2150MB응용 프로그램 실행 시 100BMB, 다중 페이지 문서의 경우 페이지 당 추가로 15MB 필요