ABBYY FlexiCapture
 >
> - 솔루션 >
- ABBYY FlexiCapture
-
ABBYY FlexiCapture란?비즈니스 프로세스에 인텔리전스를 더한 문서처리 자동화 솔루션으로 정형 및 비정형 문서에서 즉시 사용 가능한 데이터를 얻을 수 있습니다.


ABBYY FlexiCapture 는 수신된 이미지, 전자 메일 및 문서 스트림에서 중요한 데이터를 지능적으로 캡처(추출) 및 분류하여 제공합니다. 프로세스의 투명성, 정확성, 워크로드 예측 가능성을 높일 수 있는 가장 정확하고 확장성이 뛰어난 데이터&문서처리 자동화 플랫폼입니다.
ABBYY FlexiCapture 는 문서 이미지에서 필요한 데이터만 지능적으로 추출하여 DB화 할 수 있는지능형 데이터 캡처 솔루션입니다. 간단한 서식부터 복잡한 서식의 문서도 처리할 수 있으며,여러 서식이 섞여 있어도 자동으로 서식의 종류를 식별하고 분류 할 수 있습니다.▣ 정형, 비정형 문서 관계없이 특정 데이터 추출 가능▣ 혼재된 여러 서식 문서 식별 및 분류 가능▣ 처리할 문서 양이 늘어나도 손쉽게 대응 가능
ABBYY FlexiCapture 솔루션을 사용하면 문서 분류와 데이터 입력에 투입되는 리소스와 시간을 효과적으로 절감할 수 있습니다. 또한 대량 문서 처리 및 DB 구축을 위한 최적의 솔루션으로, 비교적 적은 양에서부터 방대한 양의 문서 처리에도 대응할 수 있도록 확장성을 고려하여 설계되었습니다.ABBYY FlexiCapture는 다음과 같이 어떤 종류의 문서도 처리할 수 있습니다 - 비정형 문서 (Unstructured document) : 각종 공문, 기사, 계약서와 같이 문서의 구조가 상이한 문서- 정형 문서 (Structured document, Fixed Form) :각종 가입 신청서, 신고서, 설문지, 시험 답안지와 같이 문서 포맷과 데이터의 위치가 동일한 서식- 반정형 문서 (Semi-structured document) :견적서, 발주서, 신용카드 매출전표, 병원 진료비, 약제비 등의 영수증과 같이 추출할 데이터의 종류와 구조가정해져 있지만 발행기관마다 서로 양식이 달라 데이터의 위치와 포맷, 크기가 다른 경우단일 솔루션으로 모든 문서를 처리
- 비정형 문서 (Unstructured document) : 각종 공문, 기사, 계약서와 같이 문서의 구조가 상이한 문서- 정형 문서 (Structured document, Fixed Form) :각종 가입 신청서, 신고서, 설문지, 시험 답안지와 같이 문서 포맷과 데이터의 위치가 동일한 서식- 반정형 문서 (Semi-structured document) :견적서, 발주서, 신용카드 매출전표, 병원 진료비, 약제비 등의 영수증과 같이 추출할 데이터의 종류와 구조가정해져 있지만 발행기관마다 서로 양식이 달라 데이터의 위치와 포맷, 크기가 다른 경우단일 솔루션으로 모든 문서를 처리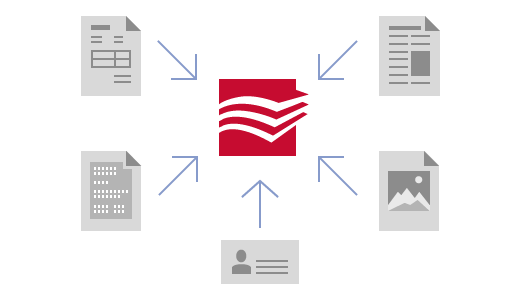 지능형 캡처 알고리즘으로 인보이스, 계약서, 신청서 등모든 종류의 문서를 처리할 수 있습니다.첨단 데이터 추출 기술인공지능 알고리즘으로 자동으로 문서 분류 및 데이터를 추출할 수 있으며,
지능형 캡처 알고리즘으로 인보이스, 계약서, 신청서 등모든 종류의 문서를 처리할 수 있습니다.첨단 데이터 추출 기술인공지능 알고리즘으로 자동으로 문서 분류 및 데이터를 추출할 수 있으며,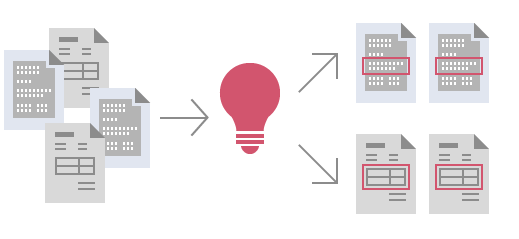 샘플 이미지에 대한 대화형 트레이닝 기능을 통해 처리 효율을 향상 시킬 수 있습니다.세계적인 OCR 인식 정확도각종 수상 경력에 빛나는 ABBYY의 OCR 및 분류 기술과 내장된 데이터 검증 규칙의
샘플 이미지에 대한 대화형 트레이닝 기능을 통해 처리 효율을 향상 시킬 수 있습니다.세계적인 OCR 인식 정확도각종 수상 경력에 빛나는 ABBYY의 OCR 및 분류 기술과 내장된 데이터 검증 규칙의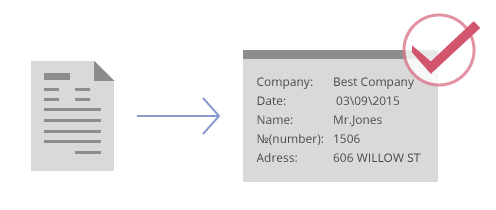 결합으로 더 정확한 데이터를 얻을 수 있습니다. 민감하거나 신뢰도가 낮은 데이터는직관적인 인터페이스를 사용하여 추가로 검증 할 수 있습니다.뛰어난 확장성ABBYY FlexiCapture는 여러 CPU Core에서 병렬로 처리할 수 있는 분산 처리 환경을
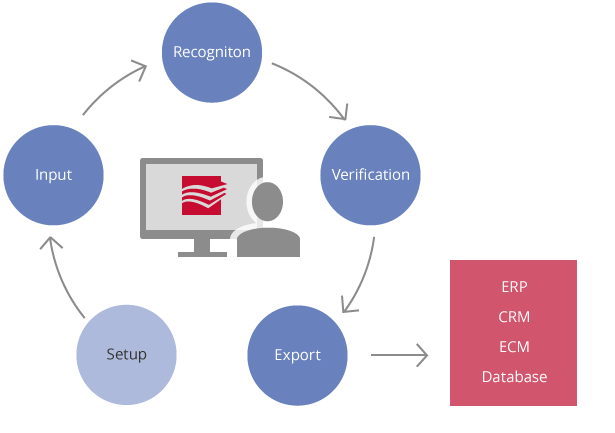
결합으로 더 정확한 데이터를 얻을 수 있습니다. 민감하거나 신뢰도가 낮은 데이터는직관적인 인터페이스를 사용하여 추가로 검증 할 수 있습니다.뛰어난 확장성ABBYY FlexiCapture는 여러 CPU Core에서 병렬로 처리할 수 있는 분산 처리 환경을 지원합니다. 대형 볼륨의 문서 처리도 대응할 수 있도록 확장성을 고려하여 설계되었습니다.워크 플로우(입력 - 분류 - 인식 -데이터 추출 - 검증 - 출력)
지원합니다. 대형 볼륨의 문서 처리도 대응할 수 있도록 확장성을 고려하여 설계되었습니다.워크 플로우(입력 - 분류 - 인식 -데이터 추출 - 검증 - 출력) 입력
입력 ABBYY FlexiCapture 는 이미지 포맷, 전자 메일에 첨부된 메시지 본문을 포함하여 TXT, EML, XLSX, VSD, HTML, DOCX, XLS, VSDX, DOC, PPTX, HTM, PPT, RTF 등 모든 Ofiice 문서를 자동으로 처리합니다. 디지털에서 생성된 Office 문서는 다음과 같이 처리할 수 있습니다.- Microsoft Office 가 설치되어 있으면 해당 설정 사용 가능, 유효한 로그인과 암호 제공- Libre Office가 설치되어 있고 설정에서 해당 사용이 허용된 경우- 위 두 개에 해당되지 않을 경우, 내장된 변환기 사용자동 문서 분류
ABBYY FlexiCapture 는 이미지 포맷, 전자 메일에 첨부된 메시지 본문을 포함하여 TXT, EML, XLSX, VSD, HTML, DOCX, XLS, VSDX, DOC, PPTX, HTM, PPT, RTF 등 모든 Ofiice 문서를 자동으로 처리합니다. 디지털에서 생성된 Office 문서는 다음과 같이 처리할 수 있습니다.- Microsoft Office 가 설치되어 있으면 해당 설정 사용 가능, 유효한 로그인과 암호 제공- Libre Office가 설치되어 있고 설정에서 해당 사용이 허용된 경우- 위 두 개에 해당되지 않을 경우, 내장된 변환기 사용자동 문서 분류 신경망 기반 자동 문서분류 기술은 문서의 유형(예: 운전면허증, 은행 명세서, 세금양식, 계약서, 송장등) 및 맞춤 하위 범주(예: A공급업체의 송장, B공급업체의 송장등 )별로 문서를 정렬할 수 있습니다.쉽게 학습 가능한 자동 분류기를 사용할 수 있습니다. 샘플 문서 세트(각 유형마다 10개 미만 문서)를 제공하고 세트의 각 문서에 대한 참조 클래스를 지정할 수 있습니다.문서 서식을 자동으로 식별하고, 한 페이지 또는 여러 페이지로 구성된 문서를 구분하는 고급 기술을 제공합니다.문서 이미지를 다음과 같이 자동으로 분류 할 수 있습니다.- 콘텐츠 기반 분류- 규칙 기반 분류- 위 규칙의 조합또한 ABBYY FlexiCapture의 문서 자동 분류 기술은 다음과 같이 복잡한 구조의 문서들도 분류해낼 수 있습니다.- 한 페이지 또는 여러 페이지 문서- 페이지 수가 가변적인 문서- 여러 페이지에 걸친 표를 포함하는 문서- 첨부 이미지를 포함하는 문서 등Classifier 훈련 기능을 사용하여 편리하게 문서 분류 템플릿을 구현할 수 있으며, 이미지 사이의 유사도를 자동으로 검출하여, 미지의 이미지가 속한 문서 유형을 파악해낼 수 있습니다.인식
신경망 기반 자동 문서분류 기술은 문서의 유형(예: 운전면허증, 은행 명세서, 세금양식, 계약서, 송장등) 및 맞춤 하위 범주(예: A공급업체의 송장, B공급업체의 송장등 )별로 문서를 정렬할 수 있습니다.쉽게 학습 가능한 자동 분류기를 사용할 수 있습니다. 샘플 문서 세트(각 유형마다 10개 미만 문서)를 제공하고 세트의 각 문서에 대한 참조 클래스를 지정할 수 있습니다.문서 서식을 자동으로 식별하고, 한 페이지 또는 여러 페이지로 구성된 문서를 구분하는 고급 기술을 제공합니다.문서 이미지를 다음과 같이 자동으로 분류 할 수 있습니다.- 콘텐츠 기반 분류- 규칙 기반 분류- 위 규칙의 조합또한 ABBYY FlexiCapture의 문서 자동 분류 기술은 다음과 같이 복잡한 구조의 문서들도 분류해낼 수 있습니다.- 한 페이지 또는 여러 페이지 문서- 페이지 수가 가변적인 문서- 여러 페이지에 걸친 표를 포함하는 문서- 첨부 이미지를 포함하는 문서 등Classifier 훈련 기능을 사용하여 편리하게 문서 분류 템플릿을 구현할 수 있으며, 이미지 사이의 유사도를 자동으로 검출하여, 미지의 이미지가 속한 문서 유형을 파악해낼 수 있습니다.인식 정확한 데이터 추출 (OCR, ICR, 바코드)한글을 포함해 세계 최고의 인식률을 자랑하는 ABBYY OCR 엔진으로 정확하게 데이터를 인식합니다.다음과 같은 데이터를 인식할 수 있습니다.- 한중일 언어를 포함한 전세계 190개 언어 인쇄체 인식(OCR)- 한국인 필체의 영,숫자 필기체 인식, 전세계 110개 언어 필기체 인식(ICR)- 1D, 2D 바코드 인식- 광범위한 체크마크에 대한 광학 인식- OCR-A, OCR-B, MICR 금융권 폰트 인식 등영문, 숫자의 경우 사용자 훈련으로 인식률을 높일 수 있습니다.자동 조립구분 기호(예: 두 문서 사이에 삽입된 빈 페이지)또는 페이지 카운터를 사용하거나, ABBYY 신경 기반 분류 알고리즘을 사용하여 여러 페이지로 된 문서를 그룹핑 할 수 있습니다.자동 유효성 검사인식 결과에 오류가 없음을 보장하기 위한 다양한 규칙을 제공합니다. 인식 과정이 끝나면 자동으로 유효성 검사가 수행되며 다음과 같은 기능이 제공됩니다.- 데이터 베이스와 비교- 내장된 유효성 검사 규칙 준수- 필드 간 합계 또는 동일 값 교차 체크- 스크립트 언어를 사용한 커스텀 체크 등추출ABBYY FlexiCapture 는 모기지 응용프로그램, 세금 신고서, 설문지, 신용카드 응용프로그램, 계약서, 청구서, 고객 전자 메일등과 같이 구조화되고 구조화되지 않은 다양한 종이 또는 디지털 태생의 문서 형식에서 자동으로 데이터를 추출합니다.
정확한 데이터 추출 (OCR, ICR, 바코드)한글을 포함해 세계 최고의 인식률을 자랑하는 ABBYY OCR 엔진으로 정확하게 데이터를 인식합니다.다음과 같은 데이터를 인식할 수 있습니다.- 한중일 언어를 포함한 전세계 190개 언어 인쇄체 인식(OCR)- 한국인 필체의 영,숫자 필기체 인식, 전세계 110개 언어 필기체 인식(ICR)- 1D, 2D 바코드 인식- 광범위한 체크마크에 대한 광학 인식- OCR-A, OCR-B, MICR 금융권 폰트 인식 등영문, 숫자의 경우 사용자 훈련으로 인식률을 높일 수 있습니다.자동 조립구분 기호(예: 두 문서 사이에 삽입된 빈 페이지)또는 페이지 카운터를 사용하거나, ABBYY 신경 기반 분류 알고리즘을 사용하여 여러 페이지로 된 문서를 그룹핑 할 수 있습니다.자동 유효성 검사인식 결과에 오류가 없음을 보장하기 위한 다양한 규칙을 제공합니다. 인식 과정이 끝나면 자동으로 유효성 검사가 수행되며 다음과 같은 기능이 제공됩니다.- 데이터 베이스와 비교- 내장된 유효성 검사 규칙 준수- 필드 간 합계 또는 동일 값 교차 체크- 스크립트 언어를 사용한 커스텀 체크 등추출ABBYY FlexiCapture 는 모기지 응용프로그램, 세금 신고서, 설문지, 신용카드 응용프로그램, 계약서, 청구서, 고객 전자 메일등과 같이 구조화되고 구조화되지 않은 다양한 종이 또는 디지털 태생의 문서 형식에서 자동으로 데이터를 추출합니다. 검증데이터 검증
검증데이터 검증
검증은 인식 결과를 사람이 육안으로 확인하여, 필요시 오류를 보정하는 단계입니다. 검증 속도를 높이고 절차를 단순화하기 위해 여러가지 효과적이고도 사용하기 쉬운 사용자 인터페이스를 제공하며, 웹 브라우저를 사용한 검증도 가능합니다. 검증은 선택적 단계이며 생략할 수 있습니다.그룹 검증전체 문서 중 동일한 형태(signs)를 일괄적으로 모아 효율적으로 검증할 수 있습니다.필드 검증데이터 필드를 하나씩 확인할 수 있습니다.문서 창에서 검증모든 데이터는 인식 결과와 원본 이미지를 나란히 보면서 확인할 수 있습니다. 필드에 수동으로 텍스트나, 메모를 입력할 수 있습니다.인식결과 내보내기 인식된 데이터와 문서 이미지는 다음과 같은 방식을 내보낼 수 있습니다.- 파일 (엑셀, CSV, 이미지 파일, PDF, PDF/A)- Microsoft SharePoint 2003/2007/2010/2013- 외부 데이터베이스 (ODBC호환)- 모든 ERP 시스템- 모든 외부 응용 프로그램 (사용자 스크립트 모듈 사용)문서세트 내보내기문서세트 이미지는 하나의 PDF파일로 내보내거나 저장 위치에 배치할 수 있지만 파일 또는 데이터베이스 레코드는 문서 세트의 구조를 설명하고 각 문서이미지에 대한 링크를 포함해야 합니다.문서세트 필드(하위 문서의 필드 포함)는 ODBS 데이터베이스 및 파일로 내보낼 수 있습니다. 하위 문서의 모든 필드는 내보내기를 설정할 때 사용할 수 있으므로 문서 섹션과 링크된 문서에서 민감한 정보를 매핑하거나 수정할 수 있습니다.웹 기반 관리 및 모니터링 콘솔
인식된 데이터와 문서 이미지는 다음과 같은 방식을 내보낼 수 있습니다.- 파일 (엑셀, CSV, 이미지 파일, PDF, PDF/A)- Microsoft SharePoint 2003/2007/2010/2013- 외부 데이터베이스 (ODBC호환)- 모든 ERP 시스템- 모든 외부 응용 프로그램 (사용자 스크립트 모듈 사용)문서세트 내보내기문서세트 이미지는 하나의 PDF파일로 내보내거나 저장 위치에 배치할 수 있지만 파일 또는 데이터베이스 레코드는 문서 세트의 구조를 설명하고 각 문서이미지에 대한 링크를 포함해야 합니다.문서세트 필드(하위 문서의 필드 포함)는 ODBS 데이터베이스 및 파일로 내보낼 수 있습니다. 하위 문서의 모든 필드는 내보내기를 설정할 때 사용할 수 있으므로 문서 섹션과 링크된 문서에서 민감한 정보를 매핑하거나 수정할 수 있습니다.웹 기반 관리 및 모니터링 콘솔 연중무휴 어느 위치에서든지 감독할 수 있는 웹 기반 관리 및 모니터링 콘솔이 포함되어 있습니다.관리자는 쉽게 유저 권한을 관리하고, 이벤트 로그를 확인할 수 있으며, 표준 보고서를 보거나 사용자 정의 성능 보고서를 생성할 수 있습니다.이메일 알림관리자는 오류, 라이선스 만료, 페이지 수 제한 등 중요한 이벤트에 대해 이메일로 알림을 수신하도록 선택할 수 있습니다. 또한 급박한 데이터 베이스 오버플로우, 디스크 공간 부족, 액세스 권한 요청, 로그인 시도 실패 등에 대해서도 알림을 받을 수 있어 능률적으로 솔루션을 관리할 수 있습니다.커스터마이즈 및 인테그레이션 옵션ABBYY FlexiCapture는 각 기업의 워크 플로우 또는 프로세싱 시나리오에 맞춰 작업할 수 있습니다
연중무휴 어느 위치에서든지 감독할 수 있는 웹 기반 관리 및 모니터링 콘솔이 포함되어 있습니다.관리자는 쉽게 유저 권한을 관리하고, 이벤트 로그를 확인할 수 있으며, 표준 보고서를 보거나 사용자 정의 성능 보고서를 생성할 수 있습니다.이메일 알림관리자는 오류, 라이선스 만료, 페이지 수 제한 등 중요한 이벤트에 대해 이메일로 알림을 수신하도록 선택할 수 있습니다. 또한 급박한 데이터 베이스 오버플로우, 디스크 공간 부족, 액세스 권한 요청, 로그인 시도 실패 등에 대해서도 알림을 받을 수 있어 능률적으로 솔루션을 관리할 수 있습니다.커스터마이즈 및 인테그레이션 옵션ABBYY FlexiCapture는 각 기업의 워크 플로우 또는 프로세싱 시나리오에 맞춰 작업할 수 있습니다 -

세계적인 기술력 지능형 캡처
지능형 캡처새로 릴리즈된 FlexiCapture 플랫폼은 머신 러닝 및 자연어 처리를 활용하여 솔루션의 성능과 가치 창출을 높여줍니다. 범용 엔터프라이즈 문서 캡처 플랫폼을 사용하면 고객 커뮤니케이션, 고객 요청, 쿼리 및 트랜잭션과 같은 운영 프로세스에서 비즈니스 크리티컬 데이터를 자동으로 분류하거나, 추출, 검증할 수 있습니다. 자동화된 머신 러닝 기술의 범위를 활용하는 차세대 플랫폼이며, 데이터 캡처 및 처리 환경을 재정의하고 오래된 엔터프라이즈 캡처 소프트웨어 복잡성을 단순화합니다.
 자동 학습(Auto-learning)
자동 학습(Auto-learning)새로운 자동학습 기능은 생산시간을 단축하고 지속적인 시스템 유지보수 기간을 줄여줍니다. 이 기술을 사용하면, 관리자는 유연하거나 불규칙한 문서의 레이아웃을 처리하도록 시스템을 교육할 수 있습니다. 또한 관리자는 자동 학습 결과를 편집, 삭제하거나 미세 조정할 수 있습니다. ABBYY의 고급 머신 러닝과 NPL(Natural Language Processing)을 이용하는 사용자의 피드백을 기반으로 시스템을 학습하고 개선할 뿐 아니라, 시스템 지원 및 유지관리 비용을 크게 절감할 수 있습니다.
 고급 문서 분류
고급 문서 분류인바운드 통신은 형식과 내용으로 분류할 수 있으므로, 조직에서 정보 중심 프로세스를 최적화할 수 있습니다. 입력되는 모든 유형의 문서를 감지하여 보다 빠른 응답시간과 신속한 의사 결정을 가능하게 하는 논리적인 양식을 적용합니다.
문서 분류 기술은 심층 학습(Convolutional Neural Networks)를 활용하고 모양이나 패턴별로 문서를 정렬할 수 있는 이미지 분류와, 통계 및 의미론적 텍스트 분석에 의존하는 텍스트 분류로 구성됩니다. ABBYY FlexiCapture 는 사용자가 이러한 기술을 개별적으로 사용하거나, 동시에 사용하는 것을 허용합니다. 기업을 위한 모든 준비 완료
기업을 위한 모든 준비 완료 확장성 및 향상된 성능
확장성 및 향상된 성능ABBYY FlexiCapture는 배포시 대용량 및 고속 문서 처리 시나리오를 지원하며 수직 및 수평으로 확장할 수 있습니다.
FlexiCapture의 아키텍처는 하루에 100만건 이상의 문서를 처리해야 하는지, 또는 분당 1,000페이지를 처리해야하는지에 상관없이 기업의 모든 처리 요구사항을 충족할 수 있게 확장 가능합니다. 시스템 운용자는 중앙 집중식 구성 및 관리를 통해 다중 서버 설치, 분산 인프라를 제어할 수 있습니다. 서비스 수준 계약 지원(Service Level Agreement Support)
서비스 수준 계약 지원(Service Level Agreement Support)SLA 모니터링은 비즈니스 운영방식의 초석입니다.
새로운 SLA 모니터링 기능으로 모니터링 및 분석을 수행하여 시스템이 최적의 결과와 성능을 제공하는 지 확인할 수 있습니다. 문서 처리 단계의 우선 순위를 설정하고 대기열의 문서 순서를 변경하여 필요한 시간을 단축할 수 있습니다. 데이터 처리 및 타이밍 요구사항을 충족시켜 시스템이 표준 보고서 및 대시보드와 함께 제공되는 지 확인할 수 있습니다. 멀티 테넌시(Multi-tenancy)
멀티 테넌시(Multi-tenancy)멀티 테넌시 기능을 사용하여 테넌트에 대한 안전하고 고립된 환경을 만들고 공통 정책을 다른 사용자에게 적용할 수 있습니다. 안전하고 중앙 집중화된 관리 도구 및 분리된 라이선스를 사용하여 설정 시간을 단축하고, 여러 작업 그룹의 데이터를 보호할 수 있습니다.
 사례 관리
사례 관리새로운 사례 관리 기능을 사용하여 모기지, 보험 또는 재무 어플리케이션과 같은 특정 프로세스, 트랜잭션 또는 사용 사례에 대한 문서 세트를 사전 정의할 수 있습니다. 미리 정의 된 사례 규칙을 통해 문서 안정성 및 규정 준수 여부를 확인하기 위해 여러 보험 또는 모기지 사례파일을 자동으로 확인합니다.
 모든 유형에 대한 하나의 솔루션
모든 유형에 대한 하나의 솔루션정교한 문서 분석을 통해 FlexiCapture는 종이 또는 디지털 문서(스프레드시트, 이미지,로고)의 영역을 감지할 수 있습니다. Word, Excel, PDF, 이메일 본문, 스캔 이미지 및 기타 디지털 이미지 문서 모두 동일한 흐름으로 처리할 수 있습니다.
 멀티 레벨 데이터 보호
멀티 레벨 데이터 보호다양한 방법을 사용하여 다양한 기밀 데이터 필드를 숨길 수 있습니다. 서로 다른 액세스 권한을 가진 운영자가 교환 및 검증할 수 있습니다. HTTPs는 사용자와 서버간에 양방향 암호화를 제공하여 데이터 차단 및 변조 공격으로부터 보호합니다.
 고급 모니터링 분석 및 도구
고급 모니터링 분석 및 도구이 도구는 문서 처리 흐름을 분석하고 비즈니스 프로세스의 연속성을 유지하며 리소스 또는 패키지를 최적화할 수 있습니다. 우선순위를 지정하여 성능을 조정하고 병목 현상을 제거하는 데 유용합니다.
 원활한 통합
원활한 통합FlexiCapture의 견고한 API 및 점진적 스크립팅은 SAP, Oracle, Microsoft, Laserfiche 등의 모든 기록 및 참여 시스템과의 긴밀한 통합을 지원합니다.
 모바일 캡처
모바일 캡처모바일 장치 및 기타 문서 소스를 사용하여 데이터를 입력하고, 데이터 가용성 및 처리 속도를 향상 시킵니다.
이미지 품질 향상 도구로 고품질의 모바일 업로드를 보장합니다. 확인 보고서는 이미지가 올바르게 업로드되고 처리될 때 알려줍니다. 다중 채널 데이터 입력
다중 채널 데이터 입력다중 채널 데이터 항목을 사용하면 MFP, 네트워크 스캐너, 전자메일, FTP, 웹 게시 또는 핫폴더 및 모바일 장치와 같은 여러 소스에서 오는 종이 및 디지털 문서를 단일 흐름으로 처리할 수 있습니다.
 즉시 사용 가능한 솔루션
즉시 사용 가능한 솔루션 빠른 시작
빠른 시작문서를 배치하기 전에 문서 처리를 시작할 수 있습니다. 시스템을 통해 일상 문서의 샘플을 실행하기만 하면, 유사한 문서의 데이터를 분류하고 추출하는 방법을 자동으로 학습합니다.
 크로스 브라우저 지원
크로스 브라우저 지원FlexiCapture HTML5 웹 스테이션은 Chrome, Firefox, safari, IE, Opera 및 기타 브라우저를 지원합니다. 워크 스테이션이 로컬, 원격 또는 웹 기반인지에 관계없이 글로벌 기업은 반응이 빠른 웹 인터페이스를 통해 원격 위치에서 관련 비즈니스 프로세스를 배포하고 관리할 수 있습니다.
 사전 패키지 솔루션
사전 패키지 솔루션FlexiCapture 플랫폼 및 모듈에 내장된 인보이스 캡처를 위한 사전정의된 추출 규칙과 모범 사례의 표준화된 규칙을 사용할 수 있습니다. 바로 사용할 수 있는 비즈니스 응용프로그램을 배포할 수 있습니다.
 문서 분류 자동화
문서 분류 자동화문서 분류 기술을 통해 여러 유형의 문서(운전 면허증, 은행 명세서, 세금 양식, 계약서, 송장 등) 및 변형된 문서 (예:다른 공급업체의 송장)을 분류할 수 있습니다. 들어오는 문서를 자동 정렬하고 사전 정의된 대상으로 라우팅할 수 있습니다.
FlexiCapture는 계층적 시스템에 결합할 수 있는 이미지, 텍스트 또는 규칙 기반 분류방법을 제공하여 최고의 직선 처리성능과 축소된 수동 검토 기능을 제공합니다. 파트너를 위한 최적의 제품
파트너를 위한 최적의 제품 범용 플랫폼
범용 플랫폼FlexiCapture Platform은 다양한 프로젝트, 시나리오 처리 및 다양한 문서 유형 처리를 위해 쉽게 확장될 수 있습니다.
다른 비즈니스 프로세스 및 정보 관리 시나리오에 완벽하게 통합될 수 있습니다. 시간 및 인력 최적화
시간 및 인력 최적화단순 프로젝트 자동 학습 기능을 통해 시스템 통합 업체 및 리셀러는 보다 더 정교한 시나리오 및 복잡한 레이아웃 등 리소스 집약적인 작업에 더욱 집중할 수 있습니다.
 유연한 사용자 정의
유연한 사용자 정의FlexiCapture Web API 및 사용자 정의 스크립트를 사용하면 맞춤 솔루션을 개발하고 특정 시나리오를 지원하며 기업 워크플로우에 쉽게 통합할 수 있습니다. 맞춤형 비즈니스 프로세스 또는 맞춤형 프로세싱 단계의 요구 사항을 충족시키고 특정 고객 작업을 향상 시키는 라우팅을 제공합니다.
 FlexiCapture 클라우드
FlexiCapture 클라우드이 플랫폼은 HTML5 웹 기반 반응형 UI를 사용하여 FlexiCapture Cloud를 통해 모든 클라우드 및 브라우저 기반 백엔드 엔터프라이즈 소프트웨어에 지능형 데이터 캡처를 제공할 수 있습니다. 하드웨어 유지관리 및 배치 비용을 줄이면서 비즈니스 프로세스에 보다 많은 유연성을 부여합니다.
-
인보이스 프로세싱
 ABBYY FlexiCapture 을 확장하여 인보이스 프로세싱을 위한 부가 기능으로 즉시 사용할 수 있습니다. 사전 정의된 설정, 유효성 검사 규칙, 고급 데이터베이스 조회, 향상된 특정 UI를 포함합니다.검증 스테이션 UI 업데이트
ABBYY FlexiCapture 을 확장하여 인보이스 프로세싱을 위한 부가 기능으로 즉시 사용할 수 있습니다. 사전 정의된 설정, 유효성 검사 규칙, 고급 데이터베이스 조회, 향상된 특정 UI를 포함합니다.검증 스테이션 UI 업데이트 ABBYY FlexiCapture 은 사용자 친화적으로 업데이트된 검증 스테이션 UI를 제공하여 더 빠르고 효율적으로 데이터를 검증할 수 있습니다.스캐닝 스테이션 커스터마이징
ABBYY FlexiCapture 은 사용자 친화적으로 업데이트된 검증 스테이션 UI를 제공하여 더 빠르고 효율적으로 데이터를 검증할 수 있습니다.스캐닝 스테이션 커스터마이징 기본 스캐닝 스테이션을 지원하는 닷넷 스크립팅 기능을 포함하며 커스터마이징을 위한 새로운 도구를 지원합니다.스캐닝 스테이션의 작업 효율성 향상을 위해 스캐닝 스테이션의 등록 매개변수에 사용될 모든 데이터를 파일 또는 데이터베이스로부터 가져올 수 있는 기능을 지원합니다.이메일 데이터 캡처
기본 스캐닝 스테이션을 지원하는 닷넷 스크립팅 기능을 포함하며 커스터마이징을 위한 새로운 도구를 지원합니다.스캐닝 스테이션의 작업 효율성 향상을 위해 스캐닝 스테이션의 등록 매개변수에 사용될 모든 데이터를 파일 또는 데이터베이스로부터 가져올 수 있는 기능을 지원합니다.이메일 데이터 캡처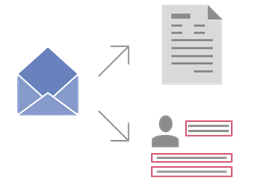 이제 추출된 데이터와 원본 이메일을 함께 저장하는것이 가능합니다.인식된 데이터에 덧붙이거나 필요한 경우 이미지 처리 중에 내보낼 수 있습니다.보낸 사람, 받는 사람, 날짜, 시간, 주제에 대한 정보를 자동으로 저장할 수 있으며, SSL 또는 TLS 암호화를 지원하는 POP3 이메일 서버로부터 가져오는 것도 지원합니다.상황에 따라 내보내기보다 유연하고 편리한 내보내기를 위해 ABBYY FlexiCapture 은 오류 규칙 또는 특정 필드의 값에 따라 내보내기 대상을 설정하는 옵션을 제공합니다.전자메일 기반 알림등록된 FlexiCapture 유저는 등록시 지정한 이메일로 알림을 받을 수 있습니다. 알림은 다음의 경우 전송됩니다.<성공적인 등록, 성공적인 암호 변경, 암호 리셋시 임시 암호 지정, 액세스 권한 부여, 거부 및 이유에 대한 관리자의 해설. >또한 FlexiCapture 관리자 및 모니터링 작업자는 오류, 라이선스 만료, 페이지 최대 한도 도달등에 대한 알림을 이메일로 받을 수 있으며, 급박한 데이터베이스 오버플로우, 디스크 공간부족, 액세스 권한에 대한 요청, 로그인 실패 등에 대해서도 알림을 받을 수 있습니다.강화된 규칙 검색 및 설정보다 편리하고 사용자 친화적인 유효성 검사 규칙 설정이 향상되었습니다. 조건에 따라 규칙을 적용하며, 유연한 규칙 검색, 필터링 및 그룹핑을 제공하는 옵션을 포함합니다.날짜 정규식날짜 정규화 설정으로, 날짜 형식이 문서 안에서 여러 변형이 있어도 표준화된 형식으로 내보낼 수 있습니다.시스템은 또한 시간 과 요일을 최종 날짜 형식에 포함할 수 있습니다.대기업 및 국제 비즈니스에 적합ABBYY FlexiCapture 솔루션 하나로 여러 언어로 작성된 문서를 처리할 수 있습니다.한중일 아시아 언어 및 영어, 라틴, 키릴 계열 포함 전세계 180개의 다국어 언어 인식(OCR)을 지원합니다.빠른 ROI 획득 및 TCO 절감 효과수기 문서 분류, 데이터 입력 등 많은 노동력을 요하는 작업을 제거함으로 빠른 투자수익률(ROI)을 얻을 수 있으며,웹 기반 클라이언트와 쉬운 구성으로 낮은 총소유비용(TCO)을 보장합니다.웹 기반 검증 작업웹 기반 데이터 검증으로, 오퍼레이터는 단순히 웹에 접속하여 검증 작업을 수행할 수 있습니다.보다 효율적으로 인력을 활용하고 비용도 절감할 수 있습니다.쉬운 배포 및 웹 기반 스캐닝온 디맨드 방식으로 어느 위치, 어떤 컴퓨터와도 원격으로 스캐닝 할 수 있습니다.스캐닝 스테이션은 자동으로 다운로드 및 설치되며, 웹 브라우저를 통해 쉽게 액세스할 수 있습니다.프론트 오피스 문서 캡처문서 처리 및 저장을 위한 추가적인 워크스테이션의 필요 없이 프론트 오피스 문서캡처 환경을 구성할 수 있도록,웹 기반 인터페이스상에서 실행 가능한 스캐닝, 검증, 웹 캡처 스테이션을 지원합니다. 문서 처리에 따른 시간, 문서 전달 비용, 종이 문서 저장공간을 감축할 수 있으며, 이러한 환경을 통해 업무프로세스의 처리속도도 개선 할 수 있습니다.최적화된 성능 및 데이터 손실 방지향상된 서버 기반 아키텍처를 통해 대량의 문서를 효율적으로 처리할 수 있습니다.강력한 처리 서버를 통해 작업을 각 처리 스테이션으로 배포하고, 처리 스테이션 전체에 대한 로드 밸런싱을 수행하는 등 리소스 집약적인 동작 프로세스들을 자동으로 수행합니다.또한 MS Cluster를 지원하여 시스템 장애로부터 데이터 손실을 방지하고 일관된 시스템 동작을 유지할 수 있습니다.유연한 워크플로우유연한 워크플로우를 지원하여 특정 비즈니스에 쉽게 적용할 수 있습니다. FlexiCapture는 기본적인 문서 프로세싱 워크플로우를 수정하기 위한 강력한 툴 세트와 사용자 정의 프로세싱 스테이지, 스크립트 및 외부 모듈을 제공합니다.또한 완전히 자동화된 모드에서 문서를 처리할 수 있습니다.훈련 기능의 모든 단계를 제어 가능단순한 몇 번의 클릭만으로 문서 레이아웃 정의 및 분류를 위한 문서 유형을 지정할 수 있습니다. 문서 레이아웃 정의는 자동으로 여러 이미지에서 추출할 요소와 데이터 필드를 지정하면 간단히 생성되며, 또한 더 높은 정확도를 달성하기 위해 문서 필드 위치에서 미세 조정 할 수 있습니다.일반적인 자동학습 시스템이 사용자 컨트롤이 전혀 불가능한데 반해 ABBYY FlexiCapture 솔루션은 사용자로 하여금 트레이닝 결과까지 모든 컨트롤이 가능한 시스템을 제공합니다.이중 검증 기능중요한 데이터 필드의 경우 검증 오퍼레이터를 이중으로 배정할 수 있는 이중 검증 환경을 제공합니다.이중 검증의 결과가 일치한 경우만 허용함으로써, 프로그램 또는 작업자의 실수를 방지할 수 있습니다.분산 검증 단계의 높은 보안성보안상의 이유로, 동일한 문서의 다른 필드를 각기 다른 오퍼레이터에 의해 검증할 수 있습니다.분산 검증 프로세스의 각 단계에서 오퍼레이터는 오직 각각이 볼 수 있는 필드에만 접근할 수 있습니다.검증 스테이션 커스터마이징표준 검증 스테이션의 한 부분으로 사용자 인터페이스에 대한 커스터마이징을 제공합니다.이 기능은 특정 오퍼레이터가 필요로 하는 추가 도구가 있거나, 특별한 규정을 준수해야 하거나, 모니터링이 필요할 때 이상적입니다. 메뉴, 도구 모음을 수정하거나, 문서 기능에 대한 컨트롤을 추가하고, 특정 시나리오에 맞게 스테이션의 동작을 변경하는 모든 요구 사항을 FlexiCapture 안에서 스크립팅할 수 있습니다.강력한 보고서ABBYY FlexiCapture 자체로 시스템 및 오퍼레이터에 대한 성능 모니터링 결과를 커스텀 리포트로 생성할 수 있습니다. 즉 크리스탈 리포트 에디터를 이용하여, FlexiCapture 내부에 저장된 데이터베이스로부터 리포트를 생성하는 기능을 제공합니다.간편한 양식(Form)디자인사용하기 쉬운 기본 설정과 드래그 앤 드롭 기능 지원, 멀티페이지 지원 및 그 이상의 쉬운 인터페이스를 통해 정적 양식을 디자인할 수 있는 가장 쉽고 빠른 방법을 제공합니다.
이제 추출된 데이터와 원본 이메일을 함께 저장하는것이 가능합니다.인식된 데이터에 덧붙이거나 필요한 경우 이미지 처리 중에 내보낼 수 있습니다.보낸 사람, 받는 사람, 날짜, 시간, 주제에 대한 정보를 자동으로 저장할 수 있으며, SSL 또는 TLS 암호화를 지원하는 POP3 이메일 서버로부터 가져오는 것도 지원합니다.상황에 따라 내보내기보다 유연하고 편리한 내보내기를 위해 ABBYY FlexiCapture 은 오류 규칙 또는 특정 필드의 값에 따라 내보내기 대상을 설정하는 옵션을 제공합니다.전자메일 기반 알림등록된 FlexiCapture 유저는 등록시 지정한 이메일로 알림을 받을 수 있습니다. 알림은 다음의 경우 전송됩니다.<성공적인 등록, 성공적인 암호 변경, 암호 리셋시 임시 암호 지정, 액세스 권한 부여, 거부 및 이유에 대한 관리자의 해설. >또한 FlexiCapture 관리자 및 모니터링 작업자는 오류, 라이선스 만료, 페이지 최대 한도 도달등에 대한 알림을 이메일로 받을 수 있으며, 급박한 데이터베이스 오버플로우, 디스크 공간부족, 액세스 권한에 대한 요청, 로그인 실패 등에 대해서도 알림을 받을 수 있습니다.강화된 규칙 검색 및 설정보다 편리하고 사용자 친화적인 유효성 검사 규칙 설정이 향상되었습니다. 조건에 따라 규칙을 적용하며, 유연한 규칙 검색, 필터링 및 그룹핑을 제공하는 옵션을 포함합니다.날짜 정규식날짜 정규화 설정으로, 날짜 형식이 문서 안에서 여러 변형이 있어도 표준화된 형식으로 내보낼 수 있습니다.시스템은 또한 시간 과 요일을 최종 날짜 형식에 포함할 수 있습니다.대기업 및 국제 비즈니스에 적합ABBYY FlexiCapture 솔루션 하나로 여러 언어로 작성된 문서를 처리할 수 있습니다.한중일 아시아 언어 및 영어, 라틴, 키릴 계열 포함 전세계 180개의 다국어 언어 인식(OCR)을 지원합니다.빠른 ROI 획득 및 TCO 절감 효과수기 문서 분류, 데이터 입력 등 많은 노동력을 요하는 작업을 제거함으로 빠른 투자수익률(ROI)을 얻을 수 있으며,웹 기반 클라이언트와 쉬운 구성으로 낮은 총소유비용(TCO)을 보장합니다.웹 기반 검증 작업웹 기반 데이터 검증으로, 오퍼레이터는 단순히 웹에 접속하여 검증 작업을 수행할 수 있습니다.보다 효율적으로 인력을 활용하고 비용도 절감할 수 있습니다.쉬운 배포 및 웹 기반 스캐닝온 디맨드 방식으로 어느 위치, 어떤 컴퓨터와도 원격으로 스캐닝 할 수 있습니다.스캐닝 스테이션은 자동으로 다운로드 및 설치되며, 웹 브라우저를 통해 쉽게 액세스할 수 있습니다.프론트 오피스 문서 캡처문서 처리 및 저장을 위한 추가적인 워크스테이션의 필요 없이 프론트 오피스 문서캡처 환경을 구성할 수 있도록,웹 기반 인터페이스상에서 실행 가능한 스캐닝, 검증, 웹 캡처 스테이션을 지원합니다. 문서 처리에 따른 시간, 문서 전달 비용, 종이 문서 저장공간을 감축할 수 있으며, 이러한 환경을 통해 업무프로세스의 처리속도도 개선 할 수 있습니다.최적화된 성능 및 데이터 손실 방지향상된 서버 기반 아키텍처를 통해 대량의 문서를 효율적으로 처리할 수 있습니다.강력한 처리 서버를 통해 작업을 각 처리 스테이션으로 배포하고, 처리 스테이션 전체에 대한 로드 밸런싱을 수행하는 등 리소스 집약적인 동작 프로세스들을 자동으로 수행합니다.또한 MS Cluster를 지원하여 시스템 장애로부터 데이터 손실을 방지하고 일관된 시스템 동작을 유지할 수 있습니다.유연한 워크플로우유연한 워크플로우를 지원하여 특정 비즈니스에 쉽게 적용할 수 있습니다. FlexiCapture는 기본적인 문서 프로세싱 워크플로우를 수정하기 위한 강력한 툴 세트와 사용자 정의 프로세싱 스테이지, 스크립트 및 외부 모듈을 제공합니다.또한 완전히 자동화된 모드에서 문서를 처리할 수 있습니다.훈련 기능의 모든 단계를 제어 가능단순한 몇 번의 클릭만으로 문서 레이아웃 정의 및 분류를 위한 문서 유형을 지정할 수 있습니다. 문서 레이아웃 정의는 자동으로 여러 이미지에서 추출할 요소와 데이터 필드를 지정하면 간단히 생성되며, 또한 더 높은 정확도를 달성하기 위해 문서 필드 위치에서 미세 조정 할 수 있습니다.일반적인 자동학습 시스템이 사용자 컨트롤이 전혀 불가능한데 반해 ABBYY FlexiCapture 솔루션은 사용자로 하여금 트레이닝 결과까지 모든 컨트롤이 가능한 시스템을 제공합니다.이중 검증 기능중요한 데이터 필드의 경우 검증 오퍼레이터를 이중으로 배정할 수 있는 이중 검증 환경을 제공합니다.이중 검증의 결과가 일치한 경우만 허용함으로써, 프로그램 또는 작업자의 실수를 방지할 수 있습니다.분산 검증 단계의 높은 보안성보안상의 이유로, 동일한 문서의 다른 필드를 각기 다른 오퍼레이터에 의해 검증할 수 있습니다.분산 검증 프로세스의 각 단계에서 오퍼레이터는 오직 각각이 볼 수 있는 필드에만 접근할 수 있습니다.검증 스테이션 커스터마이징표준 검증 스테이션의 한 부분으로 사용자 인터페이스에 대한 커스터마이징을 제공합니다.이 기능은 특정 오퍼레이터가 필요로 하는 추가 도구가 있거나, 특별한 규정을 준수해야 하거나, 모니터링이 필요할 때 이상적입니다. 메뉴, 도구 모음을 수정하거나, 문서 기능에 대한 컨트롤을 추가하고, 특정 시나리오에 맞게 스테이션의 동작을 변경하는 모든 요구 사항을 FlexiCapture 안에서 스크립팅할 수 있습니다.강력한 보고서ABBYY FlexiCapture 자체로 시스템 및 오퍼레이터에 대한 성능 모니터링 결과를 커스텀 리포트로 생성할 수 있습니다. 즉 크리스탈 리포트 에디터를 이용하여, FlexiCapture 내부에 저장된 데이터베이스로부터 리포트를 생성하는 기능을 제공합니다.간편한 양식(Form)디자인사용하기 쉬운 기본 설정과 드래그 앤 드롭 기능 지원, 멀티페이지 지원 및 그 이상의 쉬운 인터페이스를 통해 정적 양식을 디자인할 수 있는 가장 쉽고 빠른 방법을 제공합니다. -
Standalone or Distributed ?ABBYY FlexiCapture 는 새로운 비즈니스 요구사항을 충족하기 위해 쉽게 확장 할 수 있는 우수한 유연성과, 높은 스케일러블을 가지고 있는 솔루션입니다. 하나의 솔루션에서 Standalone(독립 실행모드) 및 Distributed(분산 모드)을 제공 하며, 두 설치 방식의 완벽한 호환성을 제공합니다.Standalone으로 설치를 시작한 뒤, 본격적인 분산 모드로 원활하게 마이그레이션 할 수 있습니다.Standalone(독립 실행 모드)Standalone 방식은 데스크탑 모드로, 중소 규모의 비즈니스 또는 부서 단위의 업무 목적으로 처리할 페이지가 많지 않고, 한 장소에서 이용할 때 적합합니다. 문서 가져오기, 데이터 인식, 내보내기 까지 전체 기능을 한대의 PC에서 실행합니다.Standalone 에서 지정된 모든 프로젝트 설정은 Distributed 환경에서도 유효합니다.
 Standalone 요약- 간단한 설치 및 배포- 하나의 시스템에서 모든 작업을 실행- 간단한 보안 및 권한 관리- 단순하고 완전 자동화된 워크 플로우- 단순한 통계 처리Distributed(분산 모드)대기업, BPO, 공공 프로젝트와 같이 처리할 페이지가 방대하여 여러 대의 서버에 의한 처리가 필요하거나, 여러 지역에서 처리할 필요가 있는 경우 Distributed 버전 설치가 필요합니다.
Standalone 요약- 간단한 설치 및 배포- 하나의 시스템에서 모든 작업을 실행- 간단한 보안 및 권한 관리- 단순하고 완전 자동화된 워크 플로우- 단순한 통계 처리Distributed(분산 모드)대기업, BPO, 공공 프로젝트와 같이 처리할 페이지가 방대하여 여러 대의 서버에 의한 처리가 필요하거나, 여러 지역에서 처리할 필요가 있는 경우 Distributed 버전 설치가 필요합니다.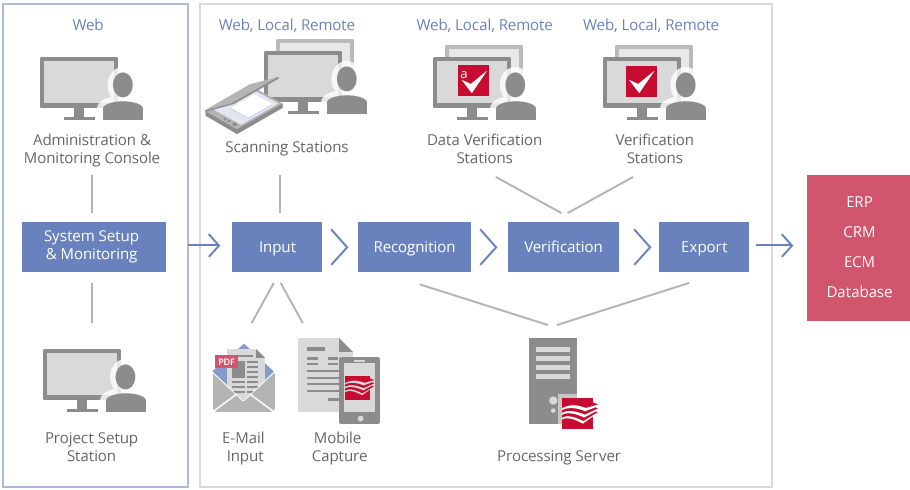 ABBYY FlexiCapture Distributed 버전은 높은 성능을 낼 수 있도록 클라이언트서버-아키텍처로 설계 되어 있으며, 처리할 페이지의 증가에 따라 확장성을 제공합니다. Distributed 버전은 데이터 처리를 위한 여러 개의 전담 서버 컴포넌트로 구성되어 있어, 로드 밸런싱 기능과 함께 최대 생산성을 구현할 수 있습니다.다수의 클라이언트 스테이션을 통해 데이터 캡처 프로젝트 셋업, 시스템 관리, 스캔, 검증, 모니터링 설정을 할 수 있으며,웹 기반 작업환경을 제공하여 웹 브라우저에서 스캔과 검증 작업을 수행할 수 있습니다. 또한 SOAP기반의 웹 서비스 API를 제공하여 시스템 통합 작업을 원할하게 할 수 있습니다.Distributed 요약- 전용 서버와 스테이션 세트 내에서 분산 캡처 설치- 자동 로드밸런싱 및 fault tolerance로 확장성이 뛰어난 프로세싱 서버- 사용자 정의 워크플로우- Windows 보안 및 고급 사용자 권한 관리- 웹 UI를 통한 프론트 오피스 문서 캡처- 웹 기반 데이터 검증 및 검증 스테이션- 웹 기반 스캐닝 클라이언트 및 클릭원스 배포- 웹 브라우저 창에서 사용할 수 있는 통계 및 보고서- 웹 서비스 API
ABBYY FlexiCapture Distributed 버전은 높은 성능을 낼 수 있도록 클라이언트서버-아키텍처로 설계 되어 있으며, 처리할 페이지의 증가에 따라 확장성을 제공합니다. Distributed 버전은 데이터 처리를 위한 여러 개의 전담 서버 컴포넌트로 구성되어 있어, 로드 밸런싱 기능과 함께 최대 생산성을 구현할 수 있습니다.다수의 클라이언트 스테이션을 통해 데이터 캡처 프로젝트 셋업, 시스템 관리, 스캔, 검증, 모니터링 설정을 할 수 있으며,웹 기반 작업환경을 제공하여 웹 브라우저에서 스캔과 검증 작업을 수행할 수 있습니다. 또한 SOAP기반의 웹 서비스 API를 제공하여 시스템 통합 작업을 원할하게 할 수 있습니다.Distributed 요약- 전용 서버와 스테이션 세트 내에서 분산 캡처 설치- 자동 로드밸런싱 및 fault tolerance로 확장성이 뛰어난 프로세싱 서버- 사용자 정의 워크플로우- Windows 보안 및 고급 사용자 권한 관리- 웹 UI를 통한 프론트 오피스 문서 캡처- 웹 기반 데이터 검증 및 검증 스테이션- 웹 기반 스캐닝 클라이언트 및 클릭원스 배포- 웹 브라우저 창에서 사용할 수 있는 통계 및 보고서- 웹 서비스 API -
시스템 요구 사항
FlexiCapture Standalone edition
- CPU: 2 GHz 이상
- OS: Windows 7 SP1, Windows 8.1, Windows 10
- RAM: 4 GB 이상
- Disk space (SSD 권장): 4 GB 이상 (설치공간 2 GB)
FlexiCapture Distributed edition
Server와 Station component로 구분되어 있으며, 분산 환경 구축 가능
1. Server (Application Server, Processing Server, Licensing Server)
- CPU: 2 GHz or faster with 2 cores
- OS: Windows Server 2008 R2 SP1, Windows Server 2012, Windows Server 2012 R2, Windows Server 2016, Windows Server 2019
- RAM: 각 컴포넌트 최소 2 GB, DB Server 설치 시 4 GB 추가
- Disk space (SSD 권장):
Application Server: 500 MB 설치 공간
Processing Server: 400 MB 설치 공간
Licensing Server: 100 MB 설치 공간
SQL Server database: 2 GB 이상
FileStorage: 추가 여유 공간 필요
- DB Server: Microsoft SQL Server 2012 SP4, 2014 SP2, 2016 SP2, 2017, 2019
- Other:
Internet Information Services 7 or higher
Microsoft .NET Framework 4.7.2 or higher (4.6 if you use Windows Server 2016)
Visual C++ 2015 Redistributable
2. Station (Processing Station, Project Setup Station, Verification Station)
- CPU: 2 GHz or faster with 2 cores
- OS: Windows 7 SP1, Windows 8.1, Windows 10, Windows Server 2008 R2 SP1 + Desktop Experience, Windows Server 2012 + Desktop Experience, Windows Server 2012 R2 + Desktop Experience, Windows Server 2016 + Desktop Experience, Windows Server 2019 + Desktop Experience
- RAM:
Processing Station: 2.5 GB for each CPU core
Project Setup Station, Verification Station: 2 GB
Scanning Station: 1 GB
- Disk space (SSD 권장):
1~4 GB 설치 공간
- Other:
Microsoft .NET Framework 4.7.2 or higher
3. HTML 5 Web Station
- CPU: 1.6 GHz or faster
- OS: Windows 7 SP1, Windows 8.1, Windows 10, Windows Server 2008 R2 SP1 + Desktop Experience, Windows Server 2012 + Desktop Experience, Windows Server 2012 R2 + Desktop Experience, Windows Server 2016 + Desktop Experience, Windows Server 2019 + Desktop Experience
- RAM: 1 GB
- Browser:
Google Chrome 및 Chromium 기반 browser를 권장
Google Chrome 55 or later
Microsoft Internet Explorer 11
Mozilla Firefox 50 or later
Microsoft Edge 41 or later
가상화 환경 지원
1. 가상 머신
Ware Workstation (any version)
Hyper-V (any version)
Oracle VirtualBox (any version)
VMWare ESXi (server included with VMWare vSphere, any version)
2. 가상 데스크톱 및 애플리케이션
VMWare Horizon 5.2.0
Citrix XenApp 7.13
3. 클라우드 서비스
Microsoft Azure
Amazon Cloud
지원하는 입력 포맷
Office files: *.doc, *.docx, *.rtf, *.htm/*.html, *.txt, *.odt, *.xls, *.xlsx, *.ods, *.ppt, *.pptx, *.odp
Image files: Adobe PDF, DjVu, GIF, JBIG2, JPEG, JPEG 2000, Microsoft HD Photo, PCX, PNG, TIFF, WIC-compatible, Windows Bitmap, XPS, DCX
지원하는 출력 포맷
Data export formats: XLS/XLSX, DBF, CSV, TXT, XML
Image export formats: TIFF, JPEG, PDF, PDF/A (Standard allows you to select the version of the format standard. By default, the version of the standard is detected automatically. For PDF/A the following standard versions are available: 1a, 1b, 2a, 2b, 2u, 3a, 3b, 3u), BMP, JPEG2000, PCX packbits, PNG
OCR 인식 언어
- 200여개 언어 지원
Abkhaz,Faroese,Lak,Russian
Adyghe,Farsi,Latin,Russian (old spelling)
Afrikaans,Fijian,Latvian,Russian with accent
Agul,Finnish,Latvian Gothic,Rwanda
Albanian,French,Lezgin,Sami (Lappish)
Altai,Frisian,Lithuanian,Samoan
Arabic (Saudi Arabia),Friulian,Luba,Scottish Gaelic
Armenian (Eastern),Gagauz,Macedonian,Selkup
Armenian (Grabar),Galician,Malagasy,Serbian (Cyrillic)
Armenian (Western),Ganda,Malay (Malaysian),Serbian (Latin)
Avar,Georgian,Malinke,Shona
Aymara,German,Maltese,Slovak
Azeri (Cyrillic),German (Luxembourg),Mansi,Slovenian
Azeri (Latin),German (new spelling),Maori,Somali
Bashkir,Greek,Mari,Sorbian
Basque,Guarani,Maya,Sotho
Belarusian,Hani,Miao,Spanish
Bemba,Hausa,Minangkabau,Sunda
Blackfoot,Hawaiian,Mohawk,Swahili
Breton,Hebrew,Mongol,Swazi
Bugotu,Hungarian,Mordvin,Swedish
Bulgarian,Icelandic,Nahuatl,Tabassaran
Burmese,Ido,Nenets,Tagalog
Buryat,Indonesian,Nivkh,Tahitian
Catalan,Ingush,Nogay,Tajik
Cebuano,Interlingua,Norwegian (Bokmal),Tatar
Chamorro,Irish,Norwegian (Nynorsk),Thai
Chechen,Italian,Nyanja,Tok Pisin
Chinese Simplified,Japanese,Occidental,Tongan
Chinese Traditional,Japanese (modern),Occitan,Tswana
Chukchee,Jingpo,Ojibway,Tun
Chuvash,Kabardian,Old English,Turkish
Corsican,Kalmyk,Old French,Turkmen (Cyrillic)
Crimean Tatar,Karachay-Balkar,Old German,Turkmen (Latin)
Croatian,Karakalpak,Old Italian,Tuvinian
Crow,Kashubian,Old Slavonic,Udmurt
Czech,Kawa,Old Spanish,Uighur (Cyrillic)
Danish,Kazakh,Ossetian,Uighur (Latin)
Dargwa,Khakass,Papiamento,Ukrainian
Dungan,Khanty,Pinyin,Uzbek (Cyrillic)
Dutch (Netherlands),Kikuyu,Polish,Uzbek (Latin)
Dutch (Belgian),Kirghiz,Portuguese,Vietnamese
English,Kongo,Portuguese (Brazil),Welsh
Eskimo (Cyrillic),Korean,Quechua (Bolivia),Wolof
Eskimo (Latin),Korean (Hangul),Rhaeto-Romanic,Xhosa
Esperanto,Koryak,Romanian,Yakut
Estonian,Kpelle,Romanian (Moldavia),Yiddish
Even,Kumyk,Romany,Zapotec
Evenki,Kurdish,Rundi,Zulu
OCR 인식 텍스트 타입
- Typographic, laser and ink-jet printers
- Typewriter
- Matrix printer
- Index

- OCR-A

- OCR-B

- MICR E-13B

- MICR CMC-7

지원 바코드 타입
- Codabar
- Codabar with checksum
- Code 128
- Code 32
- Code 39
- Code 39 with checksum
- Code 39 with asterisk
- Code 93
- DataMatrix
- EAN 13
- EAN 8
- IATA 25
- Industrial 25
- Intelligent Mail
- Interleaved 25
- Interleaved 25 with checksum
- Matrix 25
- Patch Code
- PDF 417
- Postnet
- QRCode
QR code (Version 1-40)
Micro QR Code (Version M1-M4)
- UCC-128
-&a
-
ABBYY FlexiCapture 솔루션 한눈에 알아보기
[데모동영상] 수입신고필증 데이터 추출
[데모동영상] 수입신고필증 마스킹 (Redact)
[데모동영상] 고지서 데이터 인식
[데모동영상] 사업자등록증 인식 (비정형문서 템플릿 만들기)
[데모동영상] 설문지 인식 (정형문서 처리 템플릿 만들기)
-
FlexiCapture 주요 구축 사례
주요 구축 사례 국민건강보험공단 - OCR 기술기반 팩스서식분류 & 입력자동화 시스템 개발 바로가기 국내 A 카드 - 카드가입동의서 전자문서화 시스템 구축 바로가기 슈나이더 일렉트릭 코리아 - 수입신고필증 자동화 시스템 바로가기 코엔스에너지 - 인보이스에서 필요 데이터 추출, 자동화 입력 시스템 바로가기 녹십자 - 제조기록서 전자문서화 시스템, 전국 공장 분산 설치 최대 생산성 구현 바로가기 운서관세사무소 - 수입화물 통관 문서 자동화 시스템 자동분류, 검색, DB 구축까지 바로가기 특허청 - 특허명세서(특허도면이미지)에서 도면 부호 및 위치 정보 등 필요한 데이터만 추출 바로가기 한국프라마스 - 개인작업일지 처리 OCR 솔루션 도입으로 업무효율성 3배 향상 바로가기 코오롱FnC - 카드신청서 데이터 추출 및 DB구축 바로가기 -
기능 소개 링크 1. FlexiCapture 분석 1 - 개요 바로가기 2. FlexiCapture 분석 2 - 기술 분석 바로가기 3. FlexiCapture 분석 3 - 기술 적용 바로가기 4. New 프로젝트 샘플 - 정형문서 처리 바로가기 5. New 프로젝트 샘플 - 비정형문서 처리 바로가기